 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Multivariate Time Series
Clustering multivariate time-series is the process of grouping similar time-series data with more than one timestamped variable based on their patterns and characteristics.
Papers and Code
A Semi-Supervised Pipeline for Generalized Behavior Discovery from Animal-Borne Motion Time Series
Feb 02, 2026Learning behavioral taxonomies from animal-borne sensors is challenging because labels are scarce, classes are highly imbalanced, and behaviors may be absent from the annotated set. We study generalized behavior discovery in short multivariate motion snippets from gulls, where each sample is a sequence with 3-axis IMU acceleration (20 Hz) and GPS speed, spanning nine expert-annotated behavior categories. We propose a semi-supervised discovery pipeline that (i) learns an embedding function from the labeled subset, (ii) performs label-guided clustering over embeddings of both labeled and unlabeled samples to form candidate behavior groups, and (iii) decides whether a discovered group is truly novel using a containment score. Our key contribution is a KDE + HDR (highest-density region) containment score that measures how much a discovered cluster distribution is contained within, or contains, each known-class distribution; the best-match containment score serves as an interpretable novelty statistic. In experiments where an entire behavior is withheld from supervision and appears only in the unlabeled pool, the method recovers a distinct cluster and the containment score flags novelty via low overlap, while a negative-control setting with no novel behavior yields consistently higher overlaps. These results suggest that HDR-based containment provides a practical, quantitative test for generalized class discovery in ecological motion time series under limited annotation and severe class imbalance.
MarketGANs: Multivariate financial time-series data augmentation using generative adversarial networks
Jan 25, 2026This paper introduces MarketGAN, a factor-based generative framework for high-dimensional asset return generation under severe data scarcity. We embed an explicit asset-pricing factor structure as an economic inductive bias and generate returns as a single joint vector, thereby preserving cross-sectional dependence and tail co-movement alongside inter-temporal dynamics. MarketGAN employs generative adversarial learning with a temporal convolutional network (TCN) backbone, which models stochastic, time-varying factor loadings and volatilities and captures long-range temporal dependence. Using daily returns of large U.S. equities, we find that MarketGAN more closely matches empirical stylized facts of asset returns, including heavy-tailed marginal distributions, volatility clustering, leverage effects, and, most notably, high-dimensional cross-sectional correlation structures and tail co-movement across assets, than conventional factor-model-based bootstrap approaches. In portfolio applications, covariance estimates derived from MarketGAN-generated samples outperform those derived from other methods when factor information is at least weakly informative, demonstrating tangible economic value.
TFEC: Multivariate Time-Series Clustering via Temporal-Frequency Enhanced Contrastive Learning
Jan 12, 2026Multivariate Time-Series (MTS) clustering is crucial for signal processing and data analysis. Although deep learning approaches, particularly those leveraging Contrastive Learning (CL), are prominent for MTS representation, existing CL-based models face two key limitations: 1) neglecting clustering information during positive/negative sample pair construction, and 2) introducing unreasonable inductive biases, e.g., destroying time dependence and periodicity through augmentation strategies, compromising representation quality. This paper, therefore, proposes a Temporal-Frequency Enhanced Contrastive (TFEC) learning framework. To preserve temporal structure while generating low-distortion representations, a temporal-frequency Co-EnHancement (CoEH) mechanism is introduced. Accordingly, a synergistic dual-path representation and cluster distribution learning framework is designed to jointly optimize cluster structure and representation fidelity. Experiments on six real-world benchmark datasets demonstrate TFEC's superiority, achieving 4.48% average NMI gains over SOTA methods, with ablation studies validating the design. The code of the paper is available at: https://github.com/yueliangy/TFEC.
Clustering-based Anomaly Detection in Multivariate Time Series Data
Nov 11, 2025



Multivariate time series data come as a collection of time series describing different aspects of a certain temporal phenomenon. Anomaly detection in this type of data constitutes a challenging problem yet with numerous applications in science and engineering because anomaly scores come from the simultaneous consideration of the temporal and variable relationships. In this paper, we propose a clustering-based approach to detect anomalies concerning the amplitude and the shape of multivariate time series. First, we use a sliding window to generate a set of multivariate subsequences and thereafter apply an extended fuzzy clustering to reveal a structure present within the generated multivariate subsequences. Finally, a reconstruction criterion is employed to reconstruct the multivariate subsequences with the optimal cluster centers and the partition matrix. We construct a confidence index to quantify a level of anomaly detected in the series and apply Particle Swarm Optimization as an optimization vehicle for the problem of anomaly detection. Experimental studies completed on several synthetic and six real-world datasets suggest that the proposed methods can detect the anomalies in multivariate time series. With the help of available clusters revealed by the extended fuzzy clustering, the proposed framework can detect anomalies in the multivariate time series and is suitable for identifying anomalous amplitude and shape patterns in various application domains such as health care, weather data analysis, finance, and disease outbreak detection.
* 33 pages, 20 figures
Multivariate Time series Anomaly Detection:A Framework of Hidden Markov Models
Nov 11, 2025In this study, we develop an approach to multivariate time series anomaly detection focused on the transformation of multivariate time series to univariate time series. Several transformation techniques involving Fuzzy C-Means (FCM) clustering and fuzzy integral are studied. In the sequel, a Hidden Markov Model (HMM), one of the commonly encountered statistical methods, is engaged here to detect anomalies in multivariate time series. We construct HMM-based anomaly detectors and in this context compare several transformation methods. A suite of experimental studies along with some comparative analysis is reported.
* 25 pages, 8 figures, 6 tables
Robust fuzzy clustering for high-dimensional multivariate time series with outlier detection
Oct 30, 2025

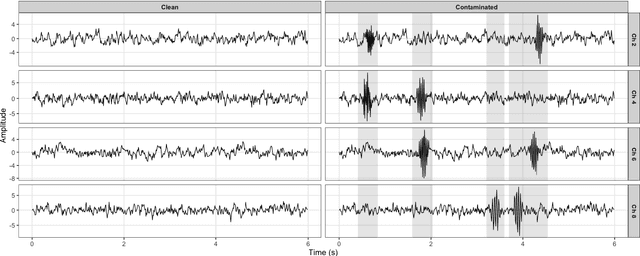

Fuzzy clustering provides a natural framework for modeling partial memberships, particularly important in multivariate time series (MTS) where state boundaries are often ambiguous. For example, in EEG monitoring of driver alertness, neural activity evolves along a continuum (from unconscious to fully alert, with many intermediate levels of drowsiness) so crisp labels are unrealistic and partial memberships are essential. However, most existing algorithms are developed for static, low-dimensional data and struggle with temporal dependence, unequal sequence lengths, high dimensionality, and contamination by noise or artifacts. To address these challenges, we introduce RFCPCA, a robust fuzzy subspace-clustering method explicitly tailored to MTS that, to the best of our knowledge, is the first of its kind to simultaneously: (i) learn membership-informed subspaces, (ii) accommodate unequal lengths and moderately high dimensions, (iii) achieve robustness through trimming, exponential reweighting, and a dedicated noise cluster, and (iv) automatically select all required hyperparameters. These components enable RFCPCA to capture latent temporal structure, provide calibrated membership uncertainty, and flag series-level outliers while remaining stable under contamination. On driver drowsiness EEG, RFCPCA improves clustering accuracy over related methods and yields a more reliable characterization of uncertainty and outlier structure in MTS.
Data-Driven Discovery of Feature Groups in Clinical Time Series
Nov 11, 2025Clinical time series data are critical for patient monitoring and predictive modeling. These time series are typically multivariate and often comprise hundreds of heterogeneous features from different data sources. The grouping of features based on similarity and relevance to the prediction task has been shown to enhance the performance of deep learning architectures. However, defining these groups a priori using only semantic knowledge is challenging, even for domain experts. To address this, we propose a novel method that learns feature groups by clustering weights of feature-wise embedding layers. This approach seamlessly integrates into standard supervised training and discovers the groups that directly improve downstream performance on clinically relevant tasks. We demonstrate that our method outperforms static clustering approaches on synthetic data and achieves performance comparable to expert-defined groups on real-world medical data. Moreover, the learned feature groups are clinically interpretable, enabling data-driven discovery of task-relevant relationships between variables.
Segmentation over Complexity: Evaluating Ensemble and Hybrid Approaches for Anomaly Detection in Industrial Time Series
Oct 30, 2025
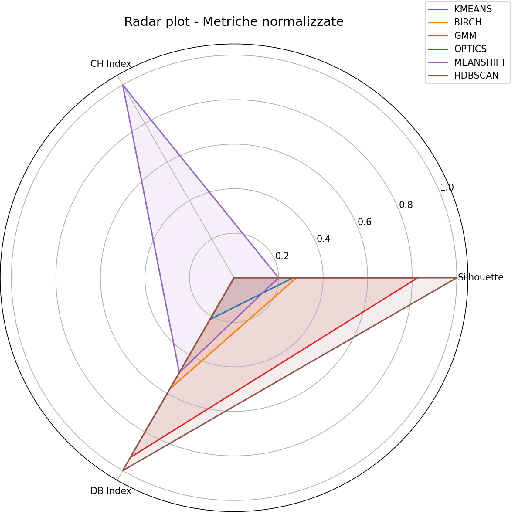


In this study, we investigate the effectiveness of advanced feature engineering and hybrid model architectures for anomaly detection in a multivariate industrial time series, focusing on a steam turbine system. We evaluate the impact of change point-derived statistical features, clustering-based substructure representations, and hybrid learning strategies on detection performance. Despite their theoretical appeal, these complex approaches consistently underperformed compared to a simple Random Forest + XGBoost ensemble trained on segmented data. The ensemble achieved an AUC-ROC of 0.976, F1-score of 0.41, and 100% early detection within the defined time window. Our findings highlight that, in scenarios with highly imbalanced and temporally uncertain data, model simplicity combined with optimized segmentation can outperform more sophisticated architectures, offering greater robustness, interpretability, and operational utility.
CLEANet: Robust and Efficient Anomaly Detection in Contaminated Multivariate Time Series
Oct 26, 2025
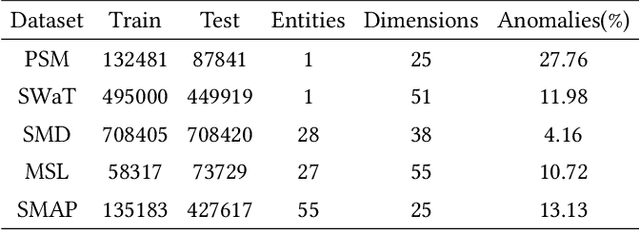
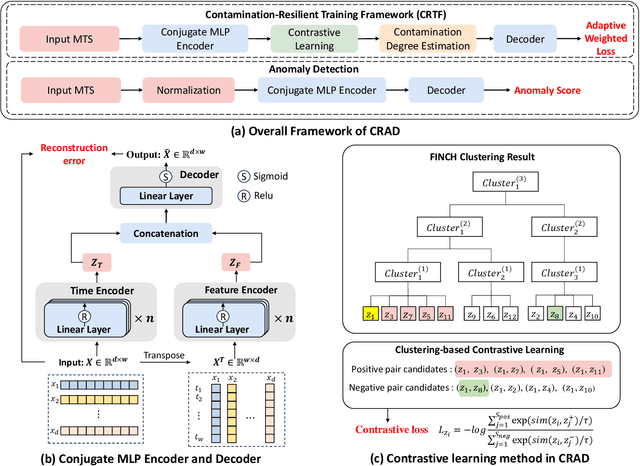
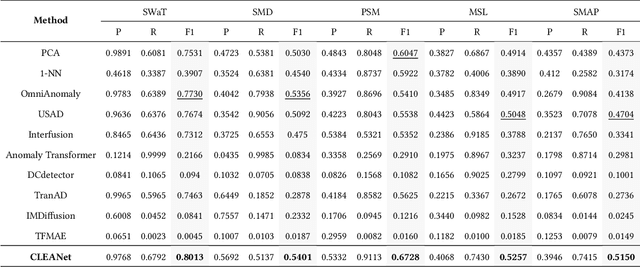
Multivariate time series (MTS) anomaly detection is essential for maintaining the reliability of industrial systems, yet real-world deployment is hindered by two critical challenges: training data contamination (noises and hidden anomalies) and inefficient model inference. Existing unsupervised methods assume clean training data, but contamination distorts learned patterns and degrades detection accuracy. Meanwhile, complex deep models often overfit to contamination and suffer from high latency, limiting practical use. To address these challenges, we propose CLEANet, a robust and efficient anomaly detection framework in contaminated multivariate time series. CLEANet introduces a Contamination-Resilient Training Framework (CRTF) that mitigates the impact of corrupted samples through an adaptive reconstruction weighting strategy combined with clustering-guided contrastive learning, thereby enhancing robustness. To further avoid overfitting on contaminated data and improve computational efficiency, we design a lightweight conjugate MLP that disentangles temporal and cross-feature dependencies. Across five public datasets, CLEANet achieves up to 73.04% higher F1 and 81.28% lower runtime compared with ten state-of-the-art baselines. Furthermore, integrating CRTF into three advanced models yields an average 5.35% F1 gain, confirming its strong generalizability.
From Patterns to Predictions: A Shapelet-Based Framework for Directional Forecasting in Noisy Financial Markets
Sep 18, 2025Directional forecasting in financial markets requires both accuracy and interpretability. Before the advent of deep learning, interpretable approaches based on human-defined patterns were prevalent, but their structural vagueness and scale ambiguity hindered generalization. In contrast, deep learning models can effectively capture complex dynamics, yet often offer limited transparency. To bridge this gap, we propose a two-stage framework that integrates unsupervised pattern extracion with interpretable forecasting. (i) SIMPC segments and clusters multivariate time series, extracting recurrent patterns that are invariant to amplitude scaling and temporal distortion, even under varying window sizes. (ii) JISC-Net is a shapelet-based classifier that uses the initial part of extracted patterns as input and forecasts subsequent partial sequences for short-term directional movement. Experiments on Bitcoin and three S&P 500 equities demonstrate that our method ranks first or second in 11 out of 12 metric--dataset combinations, consistently outperforming baselines. Unlike conventional deep learning models that output buy-or-sell signals without interpretable justification, our approach enables transparent decision-making by revealing the underlying pattern structures that drive predictive outcomes.